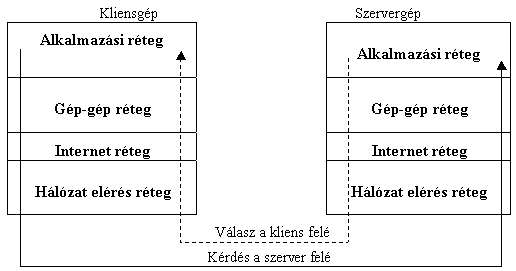
A Kliens – Szerver szerkezet
A számítógépek közötti adatcsere leginkább egy beszélgetésre hasonlít. Az egyik gép kérdez (kliensA kliens egy olyan program vagy számítógép, amely egy adott szolgáltatás igénybevételéhez szükséges. Kliens, azaz magyarul ügyfél - a mindennapi szolgáltató-ügyfél kapcsolat szóhasználatából. A kért szolgáltatást biztosító programokat vagy gépeket nevezzük kiszolgálóknak (angolul server). Kliens például az ön által használt böngészőprogram is. Ez esetben a szolgáltatást egy World Wide Web kiszolgáló biztosítja. – a szolgáltatást igénylő gép), majd a mások gép válaszol (szerverA kiszolgálók (szerverek) olyan nagyteljesítményű programok, illetve számítógépek, amelyek különböző szolgáltatásokat biztosítanak a hálózat felhasználói számára. A szolgáltatások a kliensek segítségével vehetők igénybe. Azért nevezik kiszolgálóknak őket, mert a szolgáltatásokra irányuló kéréseket szolgálják ki. – szolgáltatási kérést kiszolgálóA kiszolgálók (szerverek) olyan nagyteljesítményű programok, illetve számítógépek, amelyek különböző szolgáltatásokat biztosítanak a hálózat felhasználói számára. A szolgáltatások a kliensek segítségével vehetők igénybe. Azért nevezik kiszolgálóknak őket, mert a szolgáltatásokra irányuló kéréseket szolgálják ki. gép). Mint minden párbeszédnek, ennek is megvannak a maga szabályai. A LinuxA Linux valóban 32 bites és valóban többfelhasználós (multiuser) és többfeladatos (multitasking) operációs rendszer, szemben a DOS-szal és a Windows-zal, amely egyfeladatos és egyfelhasználós, valamint a Windows NT munkaállomással, amely többfeladatos és egyfelhasználós. A Linux írója nem egy korábbi rendszert kezdett el tökéletesítgetni, hanem elölről írta meg az operációs rendszert, felhasználva sok más programozó tapasztalatát, később programrészleteit. Linus Torvalds (egy finn egyetemista) a 80386 processzor védett módú (protected mode), feladat-váltó (task-switching) lehetőségeivel szeretett volna megismerkedni. Ez kb. 1991 nyarának elején lehetett. A program fejlesztése egy korábbi PC-s UNIX, a Minix alatt történt, eleinte assembly-ben, majd Linus áttért a C nyelvre, és a fejlesztés lényegesen gyorsabbá vált. 1991. október 5-én hirdette meg Linus az első „hivatalos”, 0.02-es Linux-ot az Interneten. Az 1991. december 19-én közzétett 0.11-es változat volt az első önálló rendszer, tehát nem kellett Minix a használatához. A 0.95-ös, 1992. márciusában kibocsájtott verziótól számíthatjuk az igazi áttörést, ettől lessz igazi népszerű operációs rendszer a Linux. Az 1.0 verziószámot csak akkor merték kiadni (1994. elején), amikor a POSIX szabvánnyal való kompatibilitás teljessé vált. Ma (2003 augusztusában) a Linux a második legelterjedtebb PC-s hálózati operációs rendszer és egyre több munkaállomáson is ez fut.. az ARPAAdvanced Reasearch Projects Agency (továbbfejlesztett kutatási projektek hivatala) modell felépítését használja a kommunikáció lebonyolításához. Az adatok az ARPAAdvanced Reasearch Projects Agency (továbbfejlesztett kutatási projektek hivatala) verem szintjein le és fel haladva jutnak az egyik gépből a másikba.
A beszélgetést a kliensA kliens egy olyan program vagy számítógép, amely egy adott szolgáltatás igénybevételéhez szükséges. Kliens, azaz magyarul ügyfél - a mindennapi szolgáltató-ügyfél kapcsolat szóhasználatából. A kért szolgáltatást biztosító programokat vagy gépeket nevezzük kiszolgálóknak (angolul server). Kliens például az ön által használt böngészőprogram is. Ez esetben a szolgáltatást egy World Wide Web kiszolgáló biztosítja. gép alkalmazási rétege kezdeményezi. Az adatTények, jelek, számok, amelyek még feldolgozást igényelnek. először lefelé halad a kliensA kliens egy olyan program vagy számítógép, amely egy adott szolgáltatás igénybevételéhez szükséges. Kliens, azaz magyarul ügyfél - a mindennapi szolgáltató-ügyfél kapcsolat szóhasználatából. A kért szolgáltatást biztosító programokat vagy gépeket nevezzük kiszolgálóknak (angolul server). Kliens például az ön által használt böngészőprogram is. Ez esetben a szolgáltatást egy World Wide Web kiszolgáló biztosítja. gép rétegei között, majd a legalsó szinten megtörténik a fizikai adatátvitelKét vagy több eszköz közötti adatcsere. Az eszközök lehetnek számítógépek, perifériák, programok stb. Az adatátvitel fő jellemzője az adatátviteli sebesség, amely nagy mértékben függ az eszközök közötti kapcsolat, összeköttetés módjától, minőségétől. a két gép között. Végül a szerverA kiszolgálók (szerverek) olyan nagyteljesítményű programok, illetve számítógépek, amelyek különböző szolgáltatásokat biztosítanak a hálózat felhasználói számára. A szolgáltatások a kliensek segítségével vehetők igénybe. Azért nevezik kiszolgálóknak őket, mert a szolgáltatásokra irányuló kéréseket szolgálják ki. gépen az adatok a rétegeken felfelé haladva eljutnak a kiszolgálóA kiszolgálók (szerverek) olyan nagyteljesítményű programok, illetve számítógépek, amelyek különböző szolgáltatásokat biztosítanak a hálózat felhasználói számára. A szolgáltatások a kliensek segítségével vehetők igénybe. Azért nevezik kiszolgálóknak őket, mert a szolgáltatásokra irányuló kéréseket szolgálják ki. alkalmazásig, amelyik a kérdést értelmezve elkészíti a válasz, majd ugyanazon az útvonalon, amelyen a kérdés érkezett elindítja visszafelé. A válasz először a szerverA kiszolgálók (szerverek) olyan nagyteljesítményű programok, illetve számítógépek, amelyek különböző szolgáltatásokat biztosítanak a hálózat felhasználói számára. A szolgáltatások a kliensek segítségével vehetők igénybe. Azért nevezik kiszolgálóknak őket, mert a szolgáltatásokra irányuló kéréseket szolgálják ki. gép alkalmazási rétegéből elindul lefelé a verem rétegein keresztül, majd a legalsó rétegen keresztül megtörténik a fizikai adatátvitelKét vagy több eszköz közötti adatcsere. Az eszközök lehetnek számítógépek, perifériák, programok stb. Az adatátvitel fő jellemzője az adatátviteli sebesség, amely nagy mértékben függ az eszközök közötti kapcsolat, összeköttetés módjától, minőségétől. a kliensA kliens egy olyan program vagy számítógép, amely egy adott szolgáltatás igénybevételéhez szükséges. Kliens, azaz magyarul ügyfél - a mindennapi szolgáltató-ügyfél kapcsolat szóhasználatából. A kért szolgáltatást biztosító programokat vagy gépeket nevezzük kiszolgálóknak (angolul server). Kliens például az ön által használt böngészőprogram is. Ez esetben a szolgáltatást egy World Wide Web kiszolgáló biztosítja. gép fel. A kliensA kliens egy olyan program vagy számítógép, amely egy adott szolgáltatás igénybevételéhez szükséges. Kliens, azaz magyarul ügyfél - a mindennapi szolgáltató-ügyfél kapcsolat szóhasználatából. A kért szolgáltatást biztosító programokat vagy gépeket nevezzük kiszolgálóknak (angolul server). Kliens például az ön által használt böngészőprogram is. Ez esetben a szolgáltatást egy World Wide Web kiszolgáló biztosítja. gépen, a legalsó rétegen keresztül felfelé haladva eljut a válasz a kliensA kliens egy olyan program vagy számítógép, amely egy adott szolgáltatás igénybevételéhez szükséges. Kliens, azaz magyarul ügyfél - a mindennapi szolgáltató-ügyfél kapcsolat szóhasználatából. A kért szolgáltatást biztosító programokat vagy gépeket nevezzük kiszolgálóknak (angolul server). Kliens például az ön által használt böngészőprogram is. Ez esetben a szolgáltatást egy World Wide Web kiszolgáló biztosítja. gép alkalmazási rétegébe, ahol megkapja a kérdést feltevő alkalmazás.
Az, hogy a kérdés és a válasz milyen típusú és milyen méretű, mindig az alkalmazásoktól függ. Minden egyes alkalmazás csak a neki megfelelő alkalmazással beszél (pl. a WWWJelenleg a leggyorsabban terjedő, legnépszerűbb szolgáltatás az Interneten a Világméretű Háló, a WWW. Sikerének oka, hogy látványos dokumentumok nézhetők vele, amik tele vannak kereszthivatkozásokkal (ez a hypertext), és képekkel, olyan, mint egy képes lexikon. A WWW általános ügyfél-kiszolgáló hálózati koncepcióra épül. Az információszolgáltató gépeken egy WWW kiszolgálóprogram (Web szerver) program fut, amely a felhasználók gépein futó böngésző-programok (Netscape, Explorer) által küldött kérésnek megfelelően elküldi a kért információt az adott gépre, amely ebben az esetben az ügyfél (kliens). Minden információkérés és az arra adott válasz független a többitől, vagyis a kapcsolat csak az átvitel idejére jön létre A kiszolgáló nem figyeli külön az egymás után beérkező igényeket, mindet új kérésként kezel, még akkor is, ha az esetleg azonos helyről érkezett. A WWW működését a gyakorlatban több tényező biztosítja: Egyetemes leírás, amellyel a különböző forrásokra lehet hivatkozni. Minden információs egység — kép, grafika, animáció, szöveg — forrásként jelenik meg a hálózaton. Ezekre a forrásokra olyan módon lehet hivatkozni a kapcsolatok felépítése során, hogy meg kell adni a forrás helyét, és annak módját, hogy a használt program hogyan tudja megjeleníteni, használni ezt a forrást. Az alkalmazott megjelenítési módot az URL (Uniform Resource Locator - egységes forrásazonosító) adja meg. böngészőA böngésző tulajdonképpen olyan szoftver, amellyel a World Wide Web hálózaton kalandozhatunk, az információk tömkelegében böngészhetünk, különböző erőforrásokat térképezhetünk fel. Ezt az oldalt valószínűleg ön is valamelyik böngészőprogram segítségével olvassa. A böngésző kliensként működve a kiszolgálókkal felveszi a kapcsolatot és azoktól különböző információkat szerez be. Egyszerű eszközöket nyújtanak az állományok feltérképezésére és letöltésére, amit egyébként a kissé nehézkesebb Archie és FTP segítségével kellene végrehajtani. A legelterjedtebb grafikus böngészők között található a Opera,a Chrome és a Mozilla Firefox. A szövegesek legelterjedtebbike a Lynx, amellyel leginkább unix operációs rendszereken találkozhatunk. a Web-szerverrel, a levelező kliensA kliens egy olyan program vagy számítógép, amely egy adott szolgáltatás igénybevételéhez szükséges. Kliens, azaz magyarul ügyfél - a mindennapi szolgáltató-ügyfél kapcsolat szóhasználatából. A kért szolgáltatást biztosító programokat vagy gépeket nevezzük kiszolgálóknak (angolul server). Kliens például az ön által használt böngészőprogram is. Ez esetben a szolgáltatást egy World Wide Web kiszolgáló biztosítja. viszont a levelező szerverrel).
A szerverek osztályozása
Több osztályozási kritérium is létezik, ezek közül az egyik a szerverA kiszolgálók (szerverek) olyan nagyteljesítményű programok, illetve számítógépek, amelyek különböző szolgáltatásokat biztosítanak a hálózat felhasználói számára. A szolgáltatások a kliensek segítségével vehetők igénybe. Azért nevezik kiszolgálóknak őket, mert a szolgáltatásokra irányuló kéréseket szolgálják ki. és a kliensA kliens egy olyan program vagy számítógép, amely egy adott szolgáltatás igénybevételéhez szükséges. Kliens, azaz magyarul ügyfél - a mindennapi szolgáltató-ügyfél kapcsolat szóhasználatából. A kért szolgáltatást biztosító programokat vagy gépeket nevezzük kiszolgálóknak (angolul server). Kliens például az ön által használt böngészőprogram is. Ez esetben a szolgáltatást egy World Wide Web kiszolgáló biztosítja. közötti kapcsolat időtartama. Ez alapján két alapvető szerver-típust különböztetünk meg:
iteratív szerverek ebben az esetben a szerverA kiszolgálók (szerverek) olyan nagyteljesítményű programok, illetve számítógépek, amelyek különböző szolgáltatásokat biztosítanak a hálózat felhasználói számára. A szolgáltatások a kliensek segítségével vehetők igénybe. Azért nevezik kiszolgálóknak őket, mert a szolgáltatásokra irányuló kéréseket szolgálják ki. maga kezeli le a kapcsolattartást. ez azt feltételezi, hogy a kérés időtartalma s a kérés kiszolgálására szolgáló erőforrások megfelelően kicsik legyenek, mint például az időszolgáltatás esetében.
konkurens szerverek azok a szolgáltatók, amelyek esetében a kérés számára szükséges erőforrásokat maga a kérés határozza meg. Ilyen például a nyomtatószerver, a hálózati fájlrendszer, az adatbázisszerverek. Ezek a szerverek, miután fogadták a kérést, egy újabb folyamatot indítanak el, amely kiszolgálja a kérést és eközben a szerverA kiszolgálók (szerverek) olyan nagyteljesítményű programok, illetve számítógépek, amelyek különböző szolgáltatásokat biztosítanak a hálózat felhasználói számára. A szolgáltatások a kliensek segítségével vehetők igénybe. Azért nevezik kiszolgálóknak őket, mert a szolgáltatásokra irányuló kéréseket szolgálják ki. maga újból várakozó állapotba mehet át, az újabb beérkező kérésekre várva.
Egy másik lehetséges kritérium az az információ-mennyiség, amely a szerverA kiszolgálók (szerverek) olyan nagyteljesítményű programok, illetve számítógépek, amelyek különböző szolgáltatásokat biztosítanak a hálózat felhasználói számára. A szolgáltatások a kliensek segítségével vehetők igénybe. Azért nevezik kiszolgálóknak őket, mert a szolgáltatásokra irányuló kéréseket szolgálják ki. rendelkezésére áll a kliensről. E kritérium alapján is két alapvető típust különböztethetünk meg:
stateful ez a szervertípus a kliensekről folyamatosan információkat tárol, tehát tudja, hogy helyesen működnek-e, vagy nem
stateless ez a típus nem tárol információkat a klienseiről
Végül a harmadik lehetséges kritérium a használt kapcsolattípus, amely szerint szintén két fő szerver-csoportot ismerünk:
kapcsolat orientált ez a szervertípus tipikusan azt feltételezi, hogy a kliensA kliens egy olyan program vagy számítógép, amely egy adott szolgáltatás igénybevételéhez szükséges. Kliens, azaz magyarul ügyfél - a mindennapi szolgáltató-ügyfél kapcsolat szóhasználatából. A kért szolgáltatást biztosító programokat vagy gépeket nevezzük kiszolgálóknak (angolul server). Kliens például az ön által használt böngészőprogram is. Ez esetben a szolgáltatást egy World Wide Web kiszolgáló biztosítja. és a szerverA kiszolgálók (szerverek) olyan nagyteljesítményű programok, illetve számítógépek, amelyek különböző szolgáltatásokat biztosítanak a hálózat felhasználói számára. A szolgáltatások a kliensek segítségével vehetők igénybe. Azért nevezik kiszolgálóknak őket, mert a szolgáltatásokra irányuló kéréseket szolgálják ki. fizikailag egymástól távol vannak és/vagy nagy megbízhatóságra van szükség és emiatt egy speciális kommunikációs csatornát tartanak fenn.
kapcsolat nélküli ez tipikusan a helyi hálózatokban működő szerverek esete, ilyen például az NFSNetwork File System A Sun Microsystems által kifejlesztett protokoll távoli gépeken, különböző típusú adattárolókon lévő file-ok elérésére és egyszerû manipulálására a hálózaton át. Az Internet egyik szabványává vált. Segítségével úgy dolgozhatunk távoli gépeken lévő file-okkal, mintha azok a saját gépünkön lennének. és NIS szolgáltatás
A továbbiakban néhány alapvető szervertípust mutatunk be.
Konkurrens szerverek
Minden, amit itt leírunk pillanatnyilag csak UNIXA unix az Interneten lévő számítógépek legelterjedtebb, nyílt operációs rendszere, amelyet 1970 körül fejlesztettek ki a Bell Laboratóriumban. A unixot arra tervezték, hogy egyszerre több felhasználó dolgozhasson rajta, és egyszerre több feladatot lehessen vele végrehajtani. A unix operációs rendszernek több fajtája, hasonmása létezik a különböző típusú, architektúrájú számítógépekre. érdemes megemlíteni a Linux operációs rendszert, amely a unixokkal rokonságot mutat. Leglényegesebb tulajdonsága, hogy ingyen terjeszthető. A fejlesztést a hálózaton keresztül - például levelezési listák segítségével - nagyon sok ember végzi./LINUX típusú operációs rendszereken érvényes. Más operációs rendszerek is rendelkeznek hasonló mechanizmusokkal. Ezek leírását az illető operációs rendszerOperating System – OS Olyan program, amely ellenőrzi a számítógép alapvető műveleteit, a periferiális egységeket, az adatszerkezeteket, lehetővé teszi a felhasználóval (operátor) történő kapcsolattartást, és programokat futtat. Kezdetben az egyes számítógép-típusokhoz külön operációs rendszereket írtak, de vannak elfogadott szabványok is (MS-DOS, UNIX), amelyek gyakorlatilag minden – arra fizikailag alkalmas – gépen futtathatók. kézikönyvében remélhetőleg meg lehet találni.
Amint fentebb már volt szó róla, a konkurens szerverA kiszolgálók (szerverek) olyan nagyteljesítményű programok, illetve számítógépek, amelyek különböző szolgáltatásokat biztosítanak a hálózat felhasználói számára. A szolgáltatások a kliensek segítségével vehetők igénybe. Azért nevezik kiszolgálóknak őket, mert a szolgáltatásokra irányuló kéréseket szolgálják ki. a kérés beérkezésének pillanatában a kérés végrehajtását átadja egy külön folyamatnak és a szerverA kiszolgálók (szerverek) olyan nagyteljesítményű programok, illetve számítógépek, amelyek különböző szolgáltatásokat biztosítanak a hálózat felhasználói számára. A szolgáltatások a kliensek segítségével vehetők igénybe. Azért nevezik kiszolgálóknak őket, mert a szolgáltatásokra irányuló kéréseket szolgálják ki. maga visszakerül a várakozó állapotába, újabb kérésekre várva. Ez tipikus UnixA unix az Interneten lévő számítógépek legelterjedtebb, nyílt operációs rendszere, amelyet 1970 körül fejlesztettek ki a Bell Laboratóriumban. A unixot arra tervezték, hogy egyszerre több felhasználó dolgozhasson rajta, és egyszerre több feladatot lehessen vele végrehajtani. A unix operációs rendszernek több fajtája, hasonmása létezik a különböző típusú, architektúrájú számítógépekre. érdemes megemlíteni a Linux operációs rendszert, amely a unixokkal rokonságot mutat. Leglényegesebb tulajdonsága, hogy ingyen terjeszthető. A fejlesztést a hálózaton keresztül - például levelezési listák segítségével - nagyon sok ember végzi. mechanizmus, az operációs rendszerOperating System – OS Olyan program, amely ellenőrzi a számítógép alapvető műveleteit, a periferiális egységeket, az adatszerkezeteket, lehetővé teszi a felhasználóval (operátor) történő kapcsolattartást, és programokat futtat. Kezdetben az egyes számítógép-típusokhoz külön operációs rendszereket írtak, de vannak elfogadott szabványok is (MS-DOS, UNIX), amelyek gyakorlatilag minden – arra fizikailag alkalmas – gépen futtathatók. alapszolgáltatásait használja. Ezek közül a fork() eljárás teszi lehetővé az új folyamatok elindítását. Ennek a rendszerhívásnak a segítségével egy kérés beérkeztekor a szerverA kiszolgálók (szerverek) olyan nagyteljesítményű programok, illetve számítógépek, amelyek különböző szolgáltatásokat biztosítanak a hálózat felhasználói számára. A szolgáltatások a kliensek segítségével vehetők igénybe. Azért nevezik kiszolgálóknak őket, mert a szolgáltatásokra irányuló kéréseket szolgálják ki. még egy példányban elindítja magát. Ez a másodpéldány fogja kiszolgálni a beérkezett kérést. A kérés kiszolgálása után ez a folyamat lezárja saját magát. Ez az alapmechanizmus teszi lehetővé, hogy mindig legyen egy szerver-folyamat, amely a beérkező kéréseket figyeli. Természetesen a valós implementációkban a helyzet egy kissé bonyolultabb, de az alapelv ugyanez.
Stateful szerver
Egy konkrét példája ennek a szervertípusnak az az eset, amikor egy nagyobb fájlból olvasunk be adatokat. A két alapvető kliensA kliens egy olyan program vagy számítógép, amely egy adott szolgáltatás igénybevételéhez szükséges. Kliens, azaz magyarul ügyfél - a mindennapi szolgáltató-ügyfél kapcsolat szóhasználatából. A kért szolgáltatást biztosító programokat vagy gépeket nevezzük kiszolgálóknak (angolul server). Kliens például az ön által használt böngészőprogram is. Ez esetben a szolgáltatást egy World Wide Web kiszolgáló biztosítja. kéréstípus a megnyitás és az olvasás. A kliensA kliens egy olyan program vagy számítógép, amely egy adott szolgáltatás igénybevételéhez szükséges. Kliens, azaz magyarul ügyfél - a mindennapi szolgáltató-ügyfél kapcsolat szóhasználatából. A kért szolgáltatást biztosító programokat vagy gépeket nevezzük kiszolgálóknak (angolul server). Kliens például az ön által használt böngészőprogram is. Ez esetben a szolgáltatást egy World Wide Web kiszolgáló biztosítja. olvasásra való megnyitást kér, válaszul egy leírót kap, amiAlternate Mark Inversion: - váltakozó 1 invertálás. A módszer nagyon hasonló az RZ módszerhez, de nullára szimmetrikus tápfeszültséget használ, így az egyenfeszültségű összetevője nulla. Minden 1-es-hez rendelt polaritás az előző 1-eshez rendelt ellentettje, a nulla szint jelöli a 0-át. Természetesen hosszú 0-s sorozatok esetén a szinkronizáció itt is problémás, de a bitbeszúrási módszer itt is használható. a fájl legfontosabb jellemzőit tartalmazza. Majd újabb kéréseket küld a szervernek. A szerverA kiszolgálók (szerverek) olyan nagyteljesítményű programok, illetve számítógépek, amelyek különböző szolgáltatásokat biztosítanak a hálózat felhasználói számára. A szolgáltatások a kliensek segítségével vehetők igénybe. Azért nevezik kiszolgálóknak őket, mert a szolgáltatásokra irányuló kéréseket szolgálják ki. meg kell jegyezze, hogy ki, milyen jogosultságokkal és milyen típusú műveletre kért hozzáférést a fájlhoz, és pontosan az állomány mely részére vonatkozik a kérés, és figyelnie kell, hogy a kliensA kliens egy olyan program vagy számítógép, amely egy adott szolgáltatás igénybevételéhez szükséges. Kliens, azaz magyarul ügyfél - a mindennapi szolgáltató-ügyfél kapcsolat szóhasználatából. A kért szolgáltatást biztosító programokat vagy gépeket nevezzük kiszolgálóknak (angolul server). Kliens például az ön által használt böngészőprogram is. Ez esetben a szolgáltatást egy World Wide Web kiszolgáló biztosítja. helyesen működik-e, ha pedig nem, akkor a kapcsolatot egyoldalúan le kell zárnia.
Stateless szerver
Az előbbi szerverA kiszolgálók (szerverek) olyan nagyteljesítményű programok, illetve számítógépek, amelyek különböző szolgáltatásokat biztosítanak a hálózat felhasználói számára. A szolgáltatások a kliensek segítségével vehetők igénybe. Azért nevezik kiszolgálóknak őket, mert a szolgáltatásokra irányuló kéréseket szolgálják ki. párja az a szolgáltatás, amely csak az adatok megjelenítését teszi lehetővé, tehát nincs megnyitási kérés, a kliensA kliens egy olyan program vagy számítógép, amely egy adott szolgáltatás igénybevételéhez szükséges. Kliens, azaz magyarul ügyfél - a mindennapi szolgáltató-ügyfél kapcsolat szóhasználatából. A kért szolgáltatást biztosító programokat vagy gépeket nevezzük kiszolgálóknak (angolul server). Kliens például az ön által használt böngészőprogram is. Ez esetben a szolgáltatást egy World Wide Web kiszolgáló biztosítja. csak olvasási parancsokat adhat és neki kell nyilvántartania ka kapcsolat minden fontos adatát.
Melyik a jobb?
A helyes válasz az, hogy attól függ… Például hálózati hiba esetén a stateless szerverA kiszolgálók (szerverek) olyan nagyteljesítményű programok, illetve számítógépek, amelyek különböző szolgáltatásokat biztosítanak a hálózat felhasználói számára. A szolgáltatások a kliensek segítségével vehetők igénybe. Azért nevezik kiszolgálóknak őket, mert a szolgáltatásokra irányuló kéréseket szolgálják ki. van előnyben, neki nem kell foglalkozzon a felmerülő problémák kezelésével, ez a kliensA kliens egy olyan program vagy számítógép, amely egy adott szolgáltatás igénybevételéhez szükséges. Kliens, azaz magyarul ügyfél - a mindennapi szolgáltató-ügyfél kapcsolat szóhasználatából. A kért szolgáltatást biztosító programokat vagy gépeket nevezzük kiszolgálóknak (angolul server). Kliens például az ön által használt böngészőprogram is. Ez esetben a szolgáltatást egy World Wide Web kiszolgáló biztosítja. dolga. A kliensA kliens egy olyan program vagy számítógép, amely egy adott szolgáltatás igénybevételéhez szükséges. Kliens, azaz magyarul ügyfél - a mindennapi szolgáltató-ügyfél kapcsolat szóhasználatából. A kért szolgáltatást biztosító programokat vagy gépeket nevezzük kiszolgálóknak (angolul server). Kliens például az ön által használt böngészőprogram is. Ez esetben a szolgáltatást egy World Wide Web kiszolgáló biztosítja. szempontjából a helyzet pontosan fordított. Más helyzetek is elképzelhetőek, a gyakorlat viszont azt mutatja, hogy minden konkrét esetben egyedileg mérlegelni kell, melyik megoldás az előnyösebb. Nincs előre meghatározott, általánosan alkalmazható recept.